|
41)
Message boards :
Number crunching :
The uploads are stuck
(Message 67800)
Posted 17 Jan 2023 by Yeti Post: It is not easy to run more than one instances of BOINC on the same hardware. If you create the new instance, the server checks if it has already seen this machine before; this happens by name and IP-Adress. As they are the same, the server assumes that you lost your last instance and cancels all former assigned tasks. You may upload already crunched results, but as the server has already cancelled these tasks, it can not use your uploads. In latest BOINC-Versions you can set an Instance-Name in cc_config.xml to avoid that the server assignes the old ID to a new instance: <device_name>HereTheNameForTheNewInstance</device_name> What to do now ? I would cancel both instances, remove them, delete them and then setup the first one. Then creating a second one, with different name via cc_config.xml and with a different directory then Instance 1 Before you start timeconsuming crunching check that the server has recognized both instances as separate machines |
|
42)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67799)
Posted 17 Jan 2023 by Yeti Post: Okay, here is the next failed WU and I ask again, why has this WU failed: https://www.cpdn.org/result.php?resultid=22268795 The machine has 32 GB RAM and was running 2 AtlasNative-tasks together with only 1 OpenIFS. If I understand the following Screenshot right, there should be plenty of RAM available: 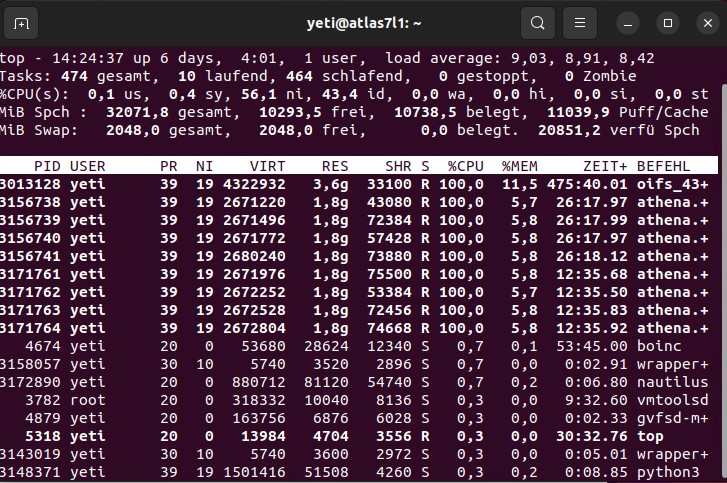 From my side, there was no interruption on the BOINC-tasks, leave tasks in memory is enabled, so, what may be or really is the problem ? |
|
43)
Message boards :
Number crunching :
The uploads are stuck
(Message 67775)
Posted 16 Jan 2023 by Yeti Post: In the last 4 hours I could upload all my backlog, but I have switched <max_file_xfers_per_project>2</max_file_xfers_per_project> from 2 to 5 in cc_config. From this moment on the upload went up much better than before |
|
44)
Message boards :
Number crunching :
The uploads are stuck
(Message 67712)
Posted 14 Jan 2023 by Yeti Post: I have stopped testing on my machines, will only crunch what has already been downloaded and wait until the backlog has cleared. Afterwards it will be time for a new try |
|
45)
Message boards :
Number crunching :
The uploads are stuck
(Message 67654)
Posted 13 Jan 2023 by Yeti Post: 1) After boot and logon, but before the BOINC client starts I think this could be easily done by starting BOINC not with systemstart, but the equivalence for a DOS-Batch with a timeout-Statement and next step then BOINC-Start On my Windows-Machines (Win7 and Win10) I have used a different-methode, the job-scheduler with "after Userlogin" and X-Minutes delay. |
|
46)
Message boards :
Number crunching :
The uploads are stuck
(Message 67651)
Posted 13 Jan 2023 by Yeti Post: It might be our old friend the staggered start Not shure if I understand this correct, but you know, that you can put BOINC to sleep after start in cc_config.xml: <start_delay>90.000000</start_delay> This pauses BOINC for 90 seconds from start, before it begins to start the different WUs. This was introduced to make windows-systemstarts smoother |
|
47)
Message boards :
Number crunching :
The uploads are stuck
(Message 67620)
Posted 12 Jan 2023 by Yeti Post: If it really troubles people to see so many uploads building up in number we can modify it for these longer model runs (3 month forecasts).HM, 121 Trickle Files for a job, that lasts between 12 and 14 hours is way to much from my view. Does each trickle contain really usefull data or only the sign "WU is still alive" ? |
|
48)
Message boards :
Number crunching :
The uploads are stuck
(Message 67588)
Posted 12 Jan 2023 by Yeti Post: climateprediction.net 12-01-2023 01:22 [error] Error reported by file upload server: Server is out of disk space |
|
49)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67587)
Posted 11 Jan 2023 by Yeti Post: On the problem machine, I have stopped Atlas-Native for the moment, rebootet and started a fresh OpenIFS. I will enshure that the VM is not restarted and monitor closely whats happening Okay, now the WU seem to have completed successfull, it has status "uploading". Now I try 2 OpenIFS at the same time, Atlas-Native still suspended |
|
50)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67553)
Posted 11 Jan 2023 by Yeti Post: Glenn, Since the only file we're interested in is the progress_file_*.xml, I wonder if you could write a small shell script ... You got me :-) On Windows no problem, will take only a few minutes, but on Linux ? Sorry, but thats my problem, I don't know how this could be done in Linux. If someone writes me the code and tells, what I should do with it, I'm willing to help, but without it's beyond my technical ability Cheers Yeti PS.: The boxes are all Ubuntu 22.04 |
|
51)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67548)
Posted 11 Jan 2023 by Yeti Post: Glenn, thank you for your reply. To keep it readable, I answer below You're right, this is one of the latest batches not the 950 batch I mentioned before. The model did work, as can be seen by the 'Uploading final trickle' message near the bottom. I have emailed CPDN about this, I'm hoping they can re-classify this as successful, give you credit and stop it going out again.Thanks ! Did this task restart at all? Even once to your knowledge? (power off, boinc client restarted?). That's the only way the task can behave like this.I'm not shure, I tried to avoid this, but may be. I think it's related to the memory in use. The total memory in the machine is not important, what is though is the memory limit you set in the boinc client. There are two values: 'When computer is in use' & 'when computer is not in use'. For example I have 35% and 75% respectively. It's quite possible the Atlas tasks are in contention with OpenIFS for memory available to boinc (not the total memory on the machine). Say you have 60% for 'when not in use', that means the total all the boinc tasks can use is 19Gb. If the Atlas tasks use ~16Gb, then OpeniFS only has ~3Gb to play with depending on what the Atlas tasks are doing. OpenIFS makes heavy use of dynamic memory and will hit a peak of ~4Gb. If that happens, then boinc will have to kick it out of memory because the client is not allowed to use enough, and that will cause the model to have to restart. I think this happens even if you have 'leave non-GPU in memory' as it's hit the client limit (I might be wrong on this).I make it short, these parameters are 90%/90%. So 28,8 GB RAM are available for BOINC. Already had done this and found the figures you posted Hope that all makes sense. If you think it's not the memory limits, let me know. The more clues I get to figure out what's going on the better.It run's on an VMWare-ESX server with RAID6 on SSDs
Two more boxes are "clones" of this VM and have both already finished two WUs each successfull, still fighting to upload them. They have less memory, run only 1x4-Core Atlas-Native (instead of 3x4) together with one OpenIFS, but they sit on older and slower hardware On the problem machine, I have stopped Atlas-Native for the moment, rebootet and started a fresh OpenIFS. I will enshure that the VM is not restarted and monitor closely whats happening Cheers, Yeti |
|
52)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67535)
Posted 11 Jan 2023 by Yeti Post: Meanwhile there are 4 failed jobs from this machine, from one I have already seen logs on the Website. Glenn, could you please take a look if it has really something to do with the faulty batch or is there a complete different reason ? https://www.cpdn.org/result.php?resultid=22282684 By the way, the box has 32 GB RAM and in max it was running 3x4-Core Atlas-Native, but these never take more than 16 GB RAM. And HD-Space is something with 70 GB free |
|
53)
Message boards :
Number crunching :
If you have used VirtualBox for BOINC and have had issues, please can you share these?
(Message 67500)
Posted 10 Jan 2023 by Yeti Post: Andrey, for my servers I switched from an early Hyper-V to VMWare and until now, my servers all are running as Guests under VMWare. So, I'm used and experienced with VMWare and switched from vBox to VMWare-Workstation, having the possibility to move a VM from a client to Server and backwards. So, I never tried anything with WSP(1/2) and if I must tell the truth, I don't like to learn this. This would cost me a lot of time again. |
|
54)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67499)
Posted 10 Jan 2023 by Yeti Post: So, I have two questions: 1) Why has the tasked crashed ? How can I find any information on this ? 2) How can I recognize, that a task is crashed, if BOINC doesn't tell anything about a crash? |
|
55)
Message boards :
Number crunching :
Why does this task fail ?
(Message 67491)
Posted 10 Jan 2023 by Yeti Post: I'm back to CPDN and tried to crunch the first WUs. On my fastest machine, the first WU failed. I checked around and found a lot of points to obey, RAM and Disk-Space and monitored all this for the second WU, but it failed again. In LOG I found: 3152 climateprediction.net 10-01-2023 12:12 Computation for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 finished 3153 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_116.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3154 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_117.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3155 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_118.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3156 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_119.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3157 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_120.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3158 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_121.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3159 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_122.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent How can the output files be absent ? This is the relevant host: https://www.cpdn.org/show_host_detail.php?hostid=1537917 Unfortunately the tasks itself doesn't show any information what has happened. Any idea ? Yeti |
|
56)
Message boards :
Number crunching :
If you have used VirtualBox for BOINC and have had issues, please can you share these?
(Message 67467)
Posted 9 Jan 2023 by Yeti Post: Okay, let me tell you my experience with vBox here. Before, please keep in mind, I'm a totally Windows-Guy, I never had something to do with Unix / Linux . When LHC@Home started first with vBox and Theory I started using vBox and lets say it worked, no big problems. When Atlas started running vBox I have immediatly started to run und support it. The mess was, problems raised more and more, so I wrote a checklist for the user how to setup a working Atlas@Home system. Here you can take a look at Version 3 (!) of this checklist: https://lhcathome.cern.ch/lhcathome/forum_thread.php?id=4161&postid=29359#29359 In this phase, the most common problems have been missing settings in BIOS (VT-X and other), not enough RAM in the Box and the computer getting sluggish if you run too much vBox-Tasks, still not using all cores. For many many years I habe run this setting in Windows 10 and it was okay.It worked in an acceptable manner. But with upcoming newer releases of vBox the whole system really got unmanageable. I got more and more tasks with the postponed Status. We never could figure out what was the real reason for this, but the postponed tasks are dead, wasted crunching time. So, I, the only Windows-Guy, never having done something with linux, has setup one VM (still with vBox) with Ubuntu 20.04 (with a lot of help from colleagues) that runs Atlas-Native. This worked like a charme and meanwhile I have one VMWare-VM (Ubuntu 22.04) on every WIndows-PC. This VM uses as many Cores and BOINC-Projekts as i want and all works fine, The HOSTs are not sluggish and I have no problems. Running hundreds of Atlas-Native without any problem. The big problem with the way, LCH@Home has realizied the vBox-Struktur is, that they run more than one VM at the same time. This costs a lot of Memory and CPU-Cykles and when the box has enough CPU-Stress, there are happening some small timeouts that make the VM unmanageable => postponed . I have run Rosetta and more Projects that use vBox-VMs, but none of them was really flawless. I have lost 1/3 of the VMs to postponed. So, I won't run any project that forces me to run several VMs of vBox. Perhaps is it possible to build a setup for WIndows, that you need only one VM (like I do now) and inside you run several tasks as if it is a real linux-System. I run 3x 4-CoreTasks Atlas-Native in most of my VMs |
|
57)
Message boards :
Number crunching :
Does CPDN support MultiCore per Task
(Message 67465)
Posted 9 Jan 2023 by Yeti Post: As Dave has already said there are plans for a multi-core OpenIFS app (not the current Hadley Centre models). I have a working version of the app in testing but there have been some issues getting it to work correctly across different machines, so for the time being it's still in development. I have already helped testing Atlas@Home in Alpha- and Development stage, if you are interested, you can use my machines (Ubuntu 22.04) for further testing. PM me if needed, I would be glad to help. |
|
58)
Message boards :
Number crunching :
Does CPDN support MultiCore per Task
(Message 67411)
Posted 7 Jan 2023 by Yeti Post: Hi, I got the info, that I can run CPDN under Linux with MultipeCores (MT). How can I configure this ? Thanks in Advance |
|
59)
Message boards :
Number crunching :
Trickle-up message
(Message 46742)
Posted 13 Aug 2013 by Yeti Post:
Same here, a Job with computation error "stucks" in my Queue, the Scheduler request succeeded, but the Job is still shown in Tasks |
|
60)
Questions and Answers :
Windows :
Unrecoverable error for result
(Message 17648)
Posted 2 Dec 2005 by Yeti Post: To Community: If you want to take a look at the host: http://climateapps2.oucs.ox.ac.uk/cpdnboinc/show_host_detail.php?hostid=271059 We have tried to run 2 other BOINC-projects on this host, they run fine. To KarlJosef: Did you give the user-account Admin-Rights for a try ? |

©2024 climateprediction.net