|
41)
Message boards :
Number crunching :
Requesting work .. \"Project has no new jobs available.\" But--
(Message 38250)
Posted 4 Nov 2009 by  Iain Inglis Iain Inglis
Post: A message has been posted somewhere Milo will see, so he should pick it up tomorrow morning. It seems to be a general problem rather than some individual preferences issue. |
|
42)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38235)
Posted 1 Nov 2009 by Iain Inglis
Post: David Glogau\'s model has come across nicely and establishes a new freeze point, north-east of the Canary Islands. 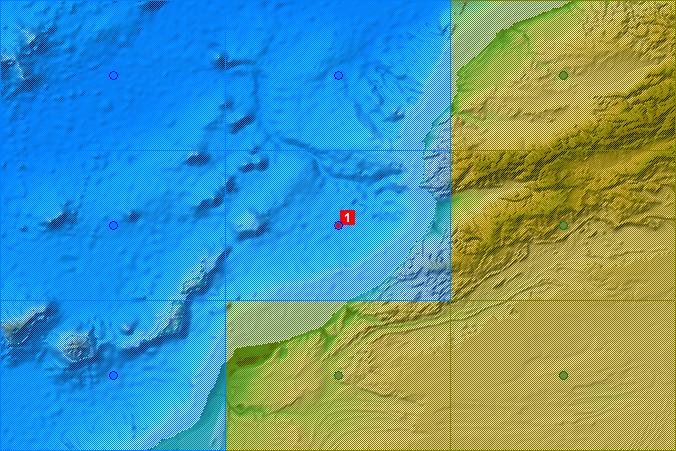 This shows that there is still considerable value in submitting Windows/Intel iceworlds, even though most of them do seem to pile up in the same place. (A Mac or Linux/AMD iceworld would nonetheless be of great interest because it would be the first to be looked at in this way, and would show whether fast-processing anomalies on those platforms have the same cause as iceworlds on Windows/Intel/AMD.) |
|
43)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38232)
Posted 31 Oct 2009 by Iain Inglis
Post: After failing to deliver one (2 weeks ago) which carried on to completion after restore, now have another iceworld. Thanks for that, Ian. Once the e-mail had been coaxed past various spam filters, it was then processed into point #19 on the West coast iceworld collection - it seems a popular spot. The model froze at 184,334 in the third phase, which follows the pattern of all other crashes, whatever phase, whatever platform - i.e. the freeze occurs in the second timestep of a block of six. The significance of that? I haven\'t a clue. |
|
44)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38231)
Posted 31 Oct 2009 by Iain Inglis
Post: iansm wrote: ... and the in-built file compression exploits the redundant repetition in areas of the same value (temperature, pressure, precipitation and cloud cover) - so the files get smaller. The reason for the progressive reduction in file size is that the model initially fails at a single grid point and that failure spreads to the whole grid in two timesteps (in your case 0:95-100k, 1:69k, 2:7k). The drop to the final value, quite a number of steps later, results from sea ice becoming uniform over the whole ocean: more repetition, more redundancy, more compression. After that, nothing happens. |
|
45)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38220)
Posted 29 Oct 2009 by Iain Inglis
Post: David, The Intel models have been added to the set of graphs now. Forewarned is normally forearmed - however, with two i7 machines the chance of anyone being ahead of you in those work units is slim. Still, you\'ll know to check the machine if the seconds/timestep heads skywards. Iain |
|
46)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38213)
Posted 28 Oct 2009 by Iain Inglis
Post: The four AMD models are as follows:OK, they\'re the ones now at http://www.bridge-9.org.uk/temp/dg/6697305.html etc. The list will be updated as models finish. I\'m rather busy for a couple of weeks, but eventually the script will be changed to create the pages from a host id, then no human intervention will be required. :-) Any idea how much the dip would be?There\'s an AMD example way back in this thread, here - second graph. |
|
47)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38211)
Posted 28 Oct 2009 by Iain Inglis
Post: I could buy another screen and put the four AMD models on it so when I am working I would see a bluey when it happens. Belt and Braces, I know.The graphics slow down the processing a lot (~50%) whereas, oddly, the recording does not. So any method that avoids actually displaying the graphics will keep your processing rate up. Once started, the recording continues until stopped, whether the graphics are showing or not. Great, so if they overwrite I don\'t need to delete, after each phase, as I should not exceed 8 * ~30GB (240GB)of data. Is that a correct understanding?Yes, that\'s how it works. This also brings up another question. Do the .tmp files stay after the model ends?BOINC seems to tidy up when the model finishes normally or is aborted. (I don\'t know what happens after a random crash, since I don\'t have them - some model types certainly used to leave debris when they crashed, but the up-to-date versions may be tidier.) A set of Web pages has been set up to track your AMD models (the Intel models will slow down so much you\'re bound to notice them). It\'s here - there are \'previous\' and \'next\' links at the bottom of the page. The pages are on a scheduled task list to be updated at 18:15 UTC each day. On an AMD, you\'re looking for a dip in the relative seconds/timestep as the model speeds up. If any iceworlds appear we can sort out communication by private message on this board. |
|
48)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38208)
Posted 28 Oct 2009 by Iain Inglis
Post: That\'s great, David. My iceworld rate is about one in seven, so you should find they start to come in pretty quickly from 19 models. Remember that AMD iceworlds are sneaky: they run fast - how you\'re going to spot those I don\'t know. (I could set up a logging script here, actually, and send you a PM heads-up; that\'s how I do my own.) I also delete the \'.cpdn\' files after each phase change (having snoozed BOINC, just in case there\'s a clash between the BOINC client writing a file and the operating system trying to delete it). I sometimes make a backup at the phase changes anyway, so it\'s a good time to do some housekeeping. (Backing up a BOINC folder with 100 GB of \'.cpdn\' files is not a good idea!) I\'ve not found any way of starting the recording automatically. However, there are command-line options for BOINC that some users know about - not me, though. Perhaps I should explore that a bit more thoroughly. What I have found is that: 1. Recording survives a phase change, at which point it will start overwriting any \'.cpdn\' files with the same name (the filename includes the timestep but not the phase). The \'.cpdn\' file itself contains a record of the current phase, so I can \'disambiguate\' without needing any other information. 2. Recording of models is independent, so BOINC will record as many models as the machine can take. However, I have found that my Q9550 just cannot handle four models recording at the same time: it runs for a few days, then all four models crash with the \'no finished file\' error. The models then restart without needing to be restored from backup, but the recording does not restart. That\'s why I take phase-change backups and record. Belt and braces. 3. Other ways of crashing the models and stopping the recording include \'looking at the disk tab in BOINC Manager\', \'looking at the tmp folder while BOINC is running\' and \'anything unusual happening on the PC\'. PS I don\'t know whether the new batch of slabs turn into iceworlds. I guess we\'ll find out. |
|
49)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38200)
Posted 28 Oct 2009 by Iain Inglis
Post: Thanks, Adrian. Only one other model is running in that work unit (6596415). When that catches up with yours then it will be apparent whether Windows/Intel computers suffer repeatable iceworlds in that work unit, or whether the iceworld on your PC was just a random freeze. It\'s a bit of a problem having to know that the iceworld is coming before it actually freezes! An occasional backup is the simplest method and the backup can also be used to recover from the random crashes that occur from time to time. Your iceworld is half way through the last phase, which means it has 12 trickles still to go. Windows/Intel slow-processing iceworlds can take about a week per trickle - so that would be 12 weeks to complete that model. You could probably do five or six other slabs in that time. Abort. Iain |
|
50)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38178)
Posted 24 Oct 2009 by Iain Inglis
Post: The collection of iceworlds now amounts to 26, with recent additions by mo.v and Dibb Fosdyke (and two of mine) - for which, many thanks! The current batch of Windows/Intel iceworlds seem all to start in the same place, on the west coast of North America. Here is the map again, together with the Mediterranean crashes. 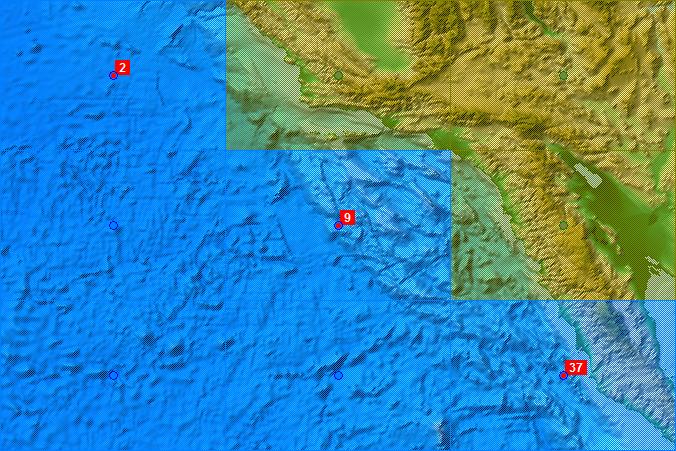 West Coast 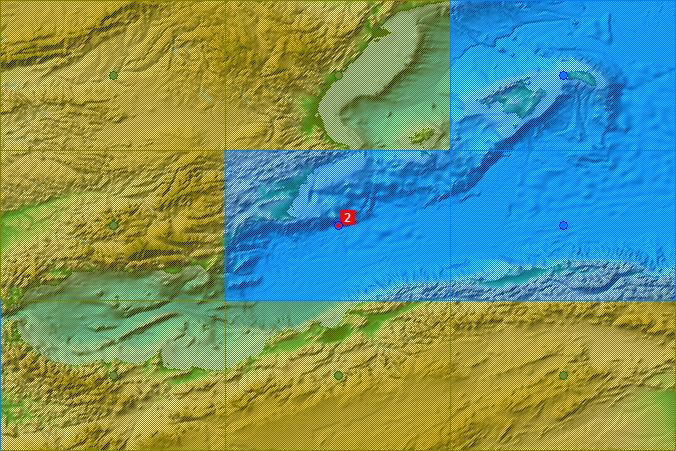 Western Med. - Straits of Gibraltar 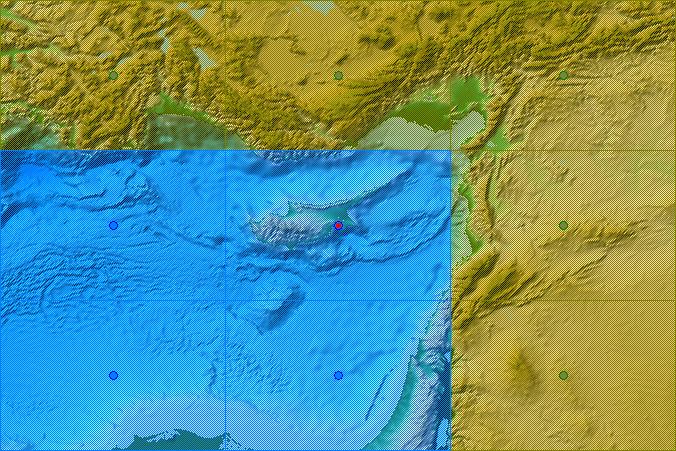 Eastern Med. - Cyprus Green and blue blobs are model grid points; the red blob is where the freeze started; a green tint indicates model land and a blue tint indicates model ocean. |
|
51)
Message boards :
Number crunching :
HadSM3dhet2
(Message 38165)
Posted 22 Oct 2009 by Iain Inglis
Post: A description is now available in the news thread, here. |
|
52)
Message boards :
Number crunching :
HadSM3dhet2
(Message 38163)
Posted 21 Oct 2009 by Iain Inglis
Post: [DJStarfox wrote:] You need someone else to explain the differences between these two types of SM3 models, because I don\'t know. We\'re looking into it! |
|
53)
Message boards :
Cafe CPDN :
Scotland team
(Message 38151)
Posted 20 Oct 2009 by Iain Inglis
Post: Congrats to Rory on completing another 160year CPDN model - his 10th such and the team\'s 160th! see stats here Great work, Rory. |
|
54)
Message boards :
Number crunching :
Long shutdowns and keeping HADSM model alive
(Message 38150)
Posted 20 Oct 2009 by Iain Inglis
Post: I may be out of date, but my impression is that the CPDN scheduler doesn\'t attempt anything clever. The reason that the WU models are being issued slowly is that there are so many WUs in the new batch. The models for each WU used to be issued sequentially so that one WU \'filled up\' quickly, but that changed (or rather I noticed it changing) with the last batch of HADSM3MH, which started to be issued \"one from one WU, then one from the next WU (not necessarily adjacent)\". This has the effect of reducing duplicates in the short term, until the scheduler has visited all WUs and they all fill up. So it makes no difference to duplication in the long run. However, there is a severe downside to the new schedule. Because the WU parameters are not set correctly, the probability of a WU being sterilised by a model failure is now much higher than before because the time between results being issued from a single WU is longer, so the chance of one of the issued models failing is higher. A failed result sterilises the WU (i.e. no more models will be issued from it). I queried the new schedule when it first appeared, but didn\'t get an explanation. It\'s probably a BOINC upgrade or some such thing. In your case, I wouldn\'t worry about the six week re-issuing - I\'ve never seen any evidence that it really happens. And if you abort the result you\'ll sterilise the work unit. [Edit: Les types quicker than I do.] |
|
55)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38136)
Posted 17 Oct 2009 by Iain Inglis
Post: Ha! I\'ve deleted most of my backups as well. My backup procedure is now to download models when there\'s about 10 days to go on the currently running set (i.e. the maximum), then immediately suspend the newly downloaded models. The current set is then run to completion, leaving four (or whatever) suspended downloads. When the completed models have reported, BOINC is then stopped and a single backup taken. The advantage of this timing is that: a) other people with faster machines get up to ten days ahead of me, so I can see the iceworlds coming (and turn on recording only when necessary) b) the downloaded models are still only Zip files, so the backup is small and quick and can be moved to another machine without \'contamination\' by the download machine. (I do quite a bit of that to check iceworld repeatability.) A reasonable \'raw\' backup history can now be kept without taking up too much space. If I\'m feeling nervous I take interim backups after phase changes (to prevent the re-uploading of Zip files), but throw them away when the new set starts and the Web site shows the right graphs for the old models. The method works best for someone like me who doesn\'t expect many crashes, but it does make the whole backup business a bit less of a chore. |
|
56)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38134)
Posted 17 Oct 2009 by Iain Inglis
Post: [iansm wrote:] As expected, since I had already aborted it before attempting the restore, we get theThat\'s my assumption too. [iansm wrote:] Looking at my records (from our team stats), have 16 fails from 146 slabs (10%) and 8 from 28 mids (30%).Looking at those mid-holocene crashes, I suspect that some of them aren\'t iceworlds (in the sense that they\'re not repeatable - they may well have frozen at the time they crashed). Have a look at this sequence of the eight potential iceworlds here; use the \'previous\' and \'next\' links at the bottom of the page to move through the sequence. I would speculate that ki3v, ki7l and km6d crashed for some other reason and could be restored from backup. It depends whether you want three CPUs down while you run them to completion! If they aren\'t reproducible iceworlds, then that brings your mid-holocene iceworld rate down from a very discouraging 8 in 28 to an almost bearable 5 in 28 (i.e. 18%). Iain |
|
57)
Questions and Answers :
Preferences :
Is there any danger to processors from intensive use?
(Message 38130)
Posted 16 Oct 2009 by Iain Inglis
Post: Not a silly question at all. A well made desktop, such as a Dell, should have no problem running at 100% so long as the ventilation is good. Since you\'re running Vista Home, I guess that you\'re running the machine at home, where there are carpets and pets and other hazards that can generate dust that accumulates inside the machine. So, I would recommend cleaning out the dust occasionally so that the cooling works effectively. I did have a power supply go on one Q6600 Dell, which they replaced under warranty: that particular machine is rather power-hungry, so I run three models on that one instead of four. On my home Q9550 I run four models at 100% as the PC doesn\'t generate anything like as much heat. There are two ways of restricting the processor usage through BOINC (apart from restricting the number of processors): if you go to your BOINC computing preferences, here, then change the last setting in the processor usage section. Alternatively, the same setting can be changed for a single machine in BOINC Manager (Advanced | Preferences). [Oops: Warped got there first.] |
|
58)
Questions and Answers :
Windows :
COmputation error
(Message 38123)
Posted 14 Oct 2009 by Iain Inglis
Post: ... I\'m guessing you don\'t have to shut off BOINC if you go into stnadby mode without actually turning the computer off ... It would be a good idea to stop BOINC in that situation, though you would have to remember to start it again when the computer comes out of hibernation. Or you could abandon hibernation and just close down as usual at the end of the day - the model will finish earlier! Though BOINC is designed to cope with lots of these kinds of situations - starting, stopping, busy computers etc. - it is nonetheless the case that it\'s exactly at these times when model errors tend to happen. If you want to complete more models then the models will have to be protected a bit (or backed up). I don\'t like making backups so I make one at the beginning of a run and take care not to crash the model before it\'s finished; other people take lots of backups and thrash their computers, restoring the backup if the model crashes. It just depends what each person wants to do. |
|
59)
Message boards :
Number crunching :
1.22 million....and out!!
(Message 38119)
Posted 13 Oct 2009 by Iain Inglis
Post: That\'s a good knock, Neil. All the best. |
|
60)
Message boards :
Number crunching :
Iceworld Appeal
(Message 38113)
Posted 13 Oct 2009 by Iain Inglis
Post: Does this mean that in the (unlikely) event that I should have a fast processing iceworld on my AMD machine I should just keep running it instead of aborting? I don\'t know the answer to that: it does mean that, practically speaking, you can keep running it. My general rule is that it isn\'t a good idea to try to guess what the project uses data for, so I assume they\'ll use anything and therefore finish anything that I can. So, if I had an AMD, I would finish an iceworld. However, unless a Windows/Intel iceworld is very near a phase boundary, the slowdown is such that it would usually be possible to run a number of complete models in the time it would take to finish one iceworld - and there I do make my own decision and abort. As to likelihood, from what I can tell, iceworlds are as prevalent on Windows/AMD and Mac (and possibly Linux/AMD) as on Windows/Intel. Windows/Intel users tend to notice because their progress will stall (and their much maligned RAC will plummet). Iceworlds on other platforms don\'t get reported because they run fast and people just don\'t notice them. The rate is something like 15% - i.e. one in seven. PS And if you do get an AMD iceworld, I would really like the \'.cpdn\' file. It would double the sample of Windows/AMD! ;-) |

©2024 climateprediction.net