Message boards :
Number crunching :
Why does this task fail ?
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
I'm back to CPDN and tried to crunch the first WUs. On my fastest machine, the first WU failed. I checked around and found a lot of points to obey, RAM and Disk-Space and monitored all this for the second WU, but it failed again. In LOG I found: 3152 climateprediction.net 10-01-2023 12:12 Computation for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 finished 3153 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_116.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3154 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_117.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3155 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_118.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3156 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_119.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3157 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_120.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3158 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_121.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent 3159 climateprediction.net 10-01-2023 12:13 Output file oifs_43r3_ps_0947_1982050100_123_951_12168591_0_r1389522811_122.zip for task oifs_43r3_ps_0947_1982050100_123_951_12168591_0 absent How can the output files be absent ? This is the relevant host: https://www.cpdn.org/show_host_detail.php?hostid=1537917 Unfortunately the tasks itself doesn't show any information what has happened. Any idea ? Yeti Supporting BOINC, a great concept ! |
|
Send message Joined: 9 Dec 05 Posts: 111 Credit: 12,112,609 RAC: 1,304 |
The output files are absent because the tasks failed and crashed. So the output files were never created. So that is outcome from crashing not the cause of it. 
|
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
So, I have two questions: 1) Why has the tasked crashed ? How can I find any information on this ? 2) How can I recognize, that a task is crashed, if BOINC doesn't tell anything about a crash? Supporting BOINC, a great concept ! |
|
Send message Joined: 6 Aug 04 Posts: 189 Credit: 27,228,000 RAC: 3,749 |
So ...The openIFS thread discusses the 'file absent' problem. If you take a look at your /var/log/syslog file for the entries around the time the task finished, there should be a mention of 'oifs_43r3_ ... file absent'. Have a look at what was happening immediately before the crash. Here, other software in the ubuntu VM was complaining and subsequently the openIFS task threw a 'file absent' wobbly. The key message from Glenn was to make sure to 'Leave non-GPU tasks in memory while suspended' (tick the box in 'Boinc - computing preferences, Disk and memory').. Since i've done this, the only two task crashes have been due to a power brown-out a couple of days ago. |
|
Send message Joined: 29 Oct 17 Posts: 885 Credit: 14,195,727 RAC: 12,314 |
Hi Yeti, I can explain what happened here. You've picked up a task from the very earliest batch (950 I think) of these oifs_43r3_ps app batches. There was a bug in the code controlling the model that I fixed before the latter batches (from 951) went out. The problem was caused because there is a separate controlling wrapper process that keeps track of the model and talks to the boinc client. The bug was such that this code lost track of where the model had got to when the model had to restart (after a power on/off, or after the cilent kicked it out of RAM). This meant the upload files got out of sequence and the boinc client then complains that it couldn't find the files it was expecting (the task has to tell the client when it starts what upload files to expect). Although the task said it failed in many cases the model still finished normally and CPDN were able to reclassify the task as succeeded in their database and award credit. This only affected a single batch, all subsequent ones were not affected by this bug though it is still possible for this to occur if certain of the task files become corrupt, say if the task is killed in the middle of writing, but that's rare now. Cheers. Glenn I'm back to CPDN and tried to crunch the first WUs. |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
Meanwhile there are 4 failed jobs from this machine, from one I have already seen logs on the Website. Glenn, could you please take a look if it has really something to do with the faulty batch or is there a complete different reason ? https://www.cpdn.org/result.php?resultid=22282684 By the way, the box has 32 GB RAM and in max it was running 3x4-Core Atlas-Native, but these never take more than 16 GB RAM. And HD-Space is something with 70 GB free Supporting BOINC, a great concept ! |
|
Send message Joined: 29 Oct 17 Posts: 885 Credit: 14,195,727 RAC: 12,314 |
Hi Yeti, You're right, this is one of the latest batches not the 950 batch I mentioned before. The model did work, as can be seen by the 'Uploading final trickle' message near the bottom. I have emailed CPDN about this, I'm hoping they can re-classify this as successful, give you credit and stop it going out again. Did this task restart at all? Even once to your knowledge? (power off, boinc client restarted?). That's the only way the task can behave like this. I think it's related to the memory in use. The total memory in the machine is not important, what is though is the memory limit you set in the boinc client. There are two values: 'When computer is in use' & 'when computer is not in use'. For example I have 35% and 75% respectively. It's quite possible the Atlas tasks are in contention with OpenIFS for memory available to boinc (not the total memory on the machine). Say you have 60% for 'when not in use', that means the total all the boinc tasks can use is 19Gb. If the Atlas tasks use ~16Gb, then OpeniFS only has ~3Gb to play with depending on what the Atlas tasks are doing. OpenIFS makes heavy use of dynamic memory and will hit a peak of ~4Gb. If that happens, then boinc will have to kick it out of memory because the client is not allowed to use enough, and that will cause the model to have to restart. I think this happens even if you have 'leave non-GPU in memory' as it's hit the client limit (I might be wrong on this). I suspect something like this is happening and when OpenIFS is kicked out of memory, any files still being written (or flushed to disk) are maybe not written properly, get corrupted and you see this message. I've not seen many tasks do this so I think it's rare but the less headroom the boinc client has for all the tasks you want to run simultaneously, I suspect the more likely this is. My advice would be to make sure that the boinc client has plenty of spare memory headroom set according to your client's memory preference. If each multicore Atlas task takes ~4Gb, OpenIFS ~4.5Gb max, the total boinc can use should match the number of tasks you would like to run concurrently, plus a bit spare. Hope that makes sense. To find the memory limit for the OpenIFS task (or any task), look in the client_state.xml file in the main boinc directory (e.g. /var/lib/boinc) and find an openifs workunit, similar to this: <workunit>
<name>oifs_43r3_ps_0582_1995050100_123_964_12181226</name>
<app_name>oifs_43r3_ps</app_name>
<version_num>105</version_num>
<rsc_fpops_est>1574400000000000.000000</rsc_fpops_est>
<rsc_fpops_bound>15744000000000000.000000</rsc_fpops_bound>
<rsc_memory_bound>6010000000.000000</rsc_memory_bound> <<<<< memory upper limit required for the task in bytes
<rsc_disk_bound>7516192768.000000</rsc_disk_bound> <<<<< disk upper limit required for the task in bytes
Do not change this file! The rsc_memory_bound is in bytes and gives the highest amount of memory required by the task (that's every process the task runs, not just the model which only uses about 4.5Gb peak). If you use that number, and the same from the Atlas workunits, you can work out what the total memory of all the tasks is and set the boinc memory bounds appropriately. You want to avoid the OpenIFS tasks being stopped & restarted due to insufficient memory as much as possible for efficiency (otherwise the model has to repeat some previous steps). Hope that all makes sense. If you think it's not the memory limits, let me know. The more clues I get to figure out what's going on the better. What kind of disk drive are you using for the slots directory that the model is running in? Is it a fast NMVe, SATA SSD, or slower HDD? May not be important but perhaps useful to know. Technical explanation: there is a small file in the slot called 'progress_info_*.xml' with some large number on the end. If you look at it, you'll see this line: <upload_file_number>49</upload_file_number>the task uses this file to keep track of which upload file number is next. The only time the task needs to read this file is when the task needs to restart after having already run a while. It reads the file to get the upload_file_number. However, if that file is not present, or its corrupt and can't be read, the code falls back to the first upload file again. That means when the model finishes, the boinc client thinks some upload files are missing. They're not, they were never used. It's a peculiarity of the boinc client that you have to declare all the upload files for the task before it starts (security I guess). I'll look into this some more and log it as an issue to address in the near future in the code. Right now I'm working on more pressing ones. Apologies for the long post. I deliberately added detail in the hope this message will be a reference for anyone else with similar problems. Cheers, Glenn Meanwhile there are 4 failed jobs from this machine, from one I have already seen logs on the Website. |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
Glenn, thank you for your reply. To keep it readable, I answer below You're right, this is one of the latest batches not the 950 batch I mentioned before. The model did work, as can be seen by the 'Uploading final trickle' message near the bottom. I have emailed CPDN about this, I'm hoping they can re-classify this as successful, give you credit and stop it going out again.Thanks ! Did this task restart at all? Even once to your knowledge? (power off, boinc client restarted?). That's the only way the task can behave like this.I'm not shure, I tried to avoid this, but may be. I think it's related to the memory in use. The total memory in the machine is not important, what is though is the memory limit you set in the boinc client. There are two values: 'When computer is in use' & 'when computer is not in use'. For example I have 35% and 75% respectively. It's quite possible the Atlas tasks are in contention with OpenIFS for memory available to boinc (not the total memory on the machine). Say you have 60% for 'when not in use', that means the total all the boinc tasks can use is 19Gb. If the Atlas tasks use ~16Gb, then OpeniFS only has ~3Gb to play with depending on what the Atlas tasks are doing. OpenIFS makes heavy use of dynamic memory and will hit a peak of ~4Gb. If that happens, then boinc will have to kick it out of memory because the client is not allowed to use enough, and that will cause the model to have to restart. I think this happens even if you have 'leave non-GPU in memory' as it's hit the client limit (I might be wrong on this).I make it short, these parameters are 90%/90%. So 28,8 GB RAM are available for BOINC. Already had done this and found the figures you posted Hope that all makes sense. If you think it's not the memory limits, let me know. The more clues I get to figure out what's going on the better.It run's on an VMWare-ESX server with RAID6 on SSDs
Two more boxes are "clones" of this VM and have both already finished two WUs each successfull, still fighting to upload them. They have less memory, run only 1x4-Core Atlas-Native (instead of 3x4) together with one OpenIFS, but they sit on older and slower hardware On the problem machine, I have stopped Atlas-Native for the moment, rebootet and started a fresh OpenIFS. I will enshure that the VM is not restarted and monitor closely whats happening Cheers, Yeti Supporting BOINC, a great concept ! |
|
Send message Joined: 29 Oct 17 Posts: 885 Credit: 14,195,727 RAC: 12,314 |
Hi Yeti, Thanks for the response. It's quite hard to judge people's technical expertise on forums. I still suspect failure to properly write the file - but what's causing it I'm guessing. The RAID probably also has a file cache before write; there are several places where files could linger before going to bare metal. Although the code executes a 'flush' command, this is still only a (strong) hint to the OS rather than an absolute command. Two more boxes are "clones" of this VM and have both already finished two WUs each successfull, still fighting to upload them. They have less memory, run only 1x4-Core Atlas-Native (instead of 3x4) together with one OpenIFS, but they sit on older and slower hardware Since the only file we're interested in is the progress_file_*.xml, I wonder if you could write a small shell script to make a frequent copy/rsync of it in each slot off to a separate location. The file will always be 8 lines long, a quick check on the file would be to run 'wc -l' and test the return is not equal to 8 to flag a bad one (and save it). Perhaps copying the files every 5 sec might be enough to catch a bad one as a single model step is roughly 20-30secs depending on cpu speed. I've been grabbing the logfiles like this myself every since I had 1 task fail, but it's never happened since. I think I'm going to add some bootstrap code that can recover the information in the progress file if it's not possible to read it. I'd still like to know the state of the file, but I don't want to take up too much of your time and it probably won't change how I deal with the issue. Glenn |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
Glenn, Since the only file we're interested in is the progress_file_*.xml, I wonder if you could write a small shell script ... You got me :-) On Windows no problem, will take only a few minutes, but on Linux ? Sorry, but thats my problem, I don't know how this could be done in Linux. If someone writes me the code and tells, what I should do with it, I'm willing to help, but without it's beyond my technical ability Cheers Yeti PS.: The boxes are all Ubuntu 22.04 Supporting BOINC, a great concept ! |
|
Send message Joined: 29 Oct 17 Posts: 885 Credit: 14,195,727 RAC: 12,314 |
No worries. I'm the same when it comes to Windows! These are tough errors to catch in the act in the wild. I know what the problem is even if I don't understand exactly what's causing it. I'm working with CPDN to modify some of the batch analysis tools to look at how common these errors are. It's impossible to eliminate everything potential thing that could go wrong. Glenn, |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
On the problem machine, I have stopped Atlas-Native for the moment, rebootet and started a fresh OpenIFS. I will enshure that the VM is not restarted and monitor closely whats happening Okay, now the WU seem to have completed successfull, it has status "uploading". Now I try 2 OpenIFS at the same time, Atlas-Native still suspended Supporting BOINC, a great concept ! |
|
Send message Joined: 18 Jul 13 Posts: 438 Credit: 24,634,419 RAC: 1,139 |
Hi, I have at least two WUs failing at the end on 100% with Exit status : 9 (0x00000009) Unknown error code One of the WUs is this one https://www.cpdn.org/result.php?resultid=22298445 I'm not sure what the issue is. |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
Okay, here is the next failed WU and I ask again, why has this WU failed: https://www.cpdn.org/result.php?resultid=22268795 The machine has 32 GB RAM and was running 2 AtlasNative-tasks together with only 1 OpenIFS. If I understand the following Screenshot right, there should be plenty of RAM available: 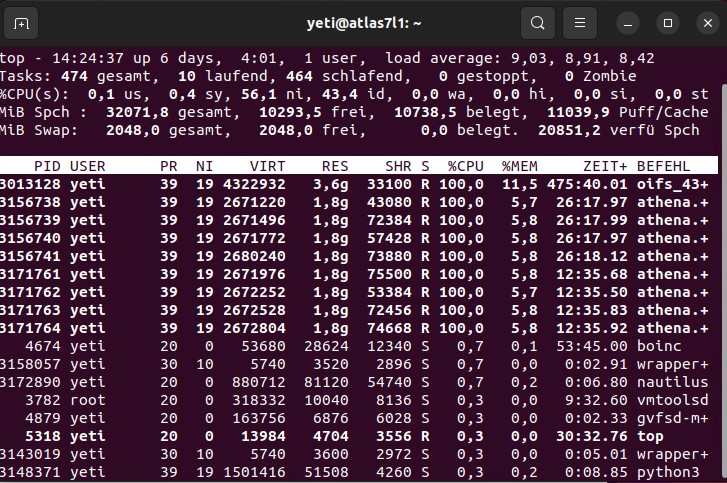 From my side, there was no interruption on the BOINC-tasks, leave tasks in memory is enabled, so, what may be or really is the problem ? Supporting BOINC, a great concept ! |
|
Send message Joined: 4 Dec 15 Posts: 52 Credit: 2,184,278 RAC: 12 |
Okay, here is the next failed WU and I ask again, why has this WU failed: https://www.cpdn.org/result.php?resultid=22268795 I'm seeing not stderr out. That's quite strange. - - - - - - - - - - Greetings, Jens |
|
Send message Joined: 28 Jul 19 Posts: 147 Credit: 12,830,559 RAC: 228 |
Okay, here is the next failed WU and I ask again, why has this WU failed: https://www.cpdn.org/result.php?resultid=22268795 And return code zero. Does that suggest that it failed in the wrapper? |
|
Send message Joined: 21 Dec 22 Posts: 5 Credit: 6,453,621 RAC: 4,198 |
One of my hosts has some WUs end with differnt error code: 194 (0x000000C2) EXIT_ABORTED_BY_CLIENT and 9 (0x00000009) Unknown error code All WUs finished all trickles and report: Uploading the final file: upload_file_122.zip https://www.cpdn.org/result.php?resultid=22273986 https://www.cpdn.org/result.php?resultid=22269585 https://www.cpdn.org/result.php?resultid=22276920 |
|
Send message Joined: 5 Aug 04 Posts: 173 Credit: 11,793,690 RAC: 35,298 |
Okay, here is the next failed WU and I ask again, why has this WU failed: https://www.cpdn.org/result.php?resultid=22268795Same client, same configuration, next WU finished successfull: https://www.cpdn.org/result.php?resultid=22269176 No Idea,what could be the reason One thing I saw in BOINC-Log after a restart: 142 17-01-2023 20:56 New system time (1673985414) < old system time (1673989026); clearing timeouts Could this have something to do with the failing OpenIFS ? Atlas-Native seem to be not effected in any way Supporting BOINC, a great concept ! |
|
Send message Joined: 12 Apr 21 Posts: 248 Credit: 12,198,315 RAC: 7,522 |
No Idea,what could be the reason I very much think that that's the reason for the failure(s). That system time issue is exactly what I was referring to in the VBox Issues thread on this forum. I have seen it multiple times and it crashes Hadley models so I wouldn't be surprised if it crashes OIFS ones too. |
 Dave Jackson Dave JacksonSend message Joined: 15 May 09 Posts: 4389 Credit: 16,820,679 RAC: 5,944 |
Worth looking at this post and also this url=https://www.cpdn.org/forum_thread.php?id=9162&postid=66949]one[/url] to see if it sheds any light on matters. Also there is a post that talks about looking in the Linux logs about the time the task failed. I will link to that post when I can track it down if no one else finds it first. (If I had more free time, I would be a lot stricter about moving posts that go ff topic which would make tracking these things down much simpler!) Glad your original post started a new thread for that reason!) |

©2024 climateprediction.net