Message boards :
Number crunching :
HADSM3DHET very slow and not an iceworld
Message board moderation
| Author | Message |
|---|---|
 GrimmReaperSound GrimmReaperSoundSend message Joined: 21 May 05 Posts: 13 Credit: 5,071,799 RAC: 98 |
I\'m running Boinc 6.4.7 on a Linux Fedora Core 9. I\'m running an HADSM3DHET model. The graphics look OK (not an iceworld) but I\'ve been running this model for almost a month now 24/7 at 95% CPU and only get: CPU Time 7:19:14 Progress 0.896% To Completion: 1831:51:07 (and climbing) The model is in Phase 1 of 3, 6969 of 259248 timesteps. I\'ve run into this problem on the last 2-3 models and aborted them after a week or so. I decided to give this one a longer run before aborting. There are no trickles even when a force an update. Needless to say my credits have flatlined. Anybody have any ideas about what is going on? Michel ----------------------------------------------- Always keep an open mind, even Einstein could not explain how the universe worked,... |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
Hi GrimmReaper (I\'ll try not to be terrified by your name.) I don\'t think that\'s the fastest computer running CPDN, but there\'s plenty of memory and your HadAM3Ps completed. This is the computer and here are your models. How many HadSM models show in the Tasks tab of your Boinc Manager? I\'m wondering why three are listed as in progress and why on both 15 and 28 October you had to abort three models within half an hour. That\'s a single-core computer so I think it should only be sent one of these models at a time. The situation looks bizarre. Could you please identify which model you were talking about? Cpdn news |
|
geophi Send message Joined: 7 Aug 04 Posts: 2169 Credit: 64,550,109 RAC: 6,649 |
Is this PC doing anything else other than crunching cpdn? It appears the last trickle that PC uploaded was on October 3rd for this model. Do you remember changing any hardware or software in early October? |
|
GrimmReaperSound Send message Joined: 21 May 05 Posts: 13 Credit: 5,071,799 RAC: 98 |
Ive got one model only presently running, task ID 10446381 (name in task managerhadsm3dhet2_u22p_006479987_5). I did two aborts, one on the 15th and one on the 28th. On both dates, the task I got when I aborted were not starting properly. I got iceworlds very quickly. So I aborted those (rwo on each occasion). The ones that did start ok I let run. But they ran very slowly even if the graphics did not show an iceworld. The computer is basically a file server for my home studio. The only real computing it does is for Boinc running only CPDN. The last changes done to this computer was early 2009 when I installed more RAM, changed HDD and added and external drive. It has been happily running Boinc until early october when I noticed the stats going down. That is when I checked and found the very slow running model. I\'ve been having this problem since then. Michel ----------------------------------------------- Always keep an open mind, even Einstein could not explain how the universe worked,... |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
This is the model. Somebody else with Linux has completed it. You say its graphics are normal eg lots of different temperatures? Is this computer overclocked? I don\'t like the fact that two other models of the same type quickly turned into iceworlds, as if there were some instability in the computer. I can\'t see what\'s wrong with the model except that it we know it\'s processing slowly as iceworlds do. I think you should just get rid of it = abort to avoid wasting more time. But first choose HadAM3P in your account, in your CPDN preferences. Then update CPDN in the Boinc manager Projects tab to tell the server about your change. Then abort. Don\'t select HadSMMH as these Mid-Holocenes can also suffer from iceworlds. HadAM3P shouldn\'t. I\'m afraid that\'s all I can suggest as I\'ve never seen this phenomenon before. Please let us know whether HadAM3P advances normally. Cpdn news |
|
GrimmReaperSound Send message Joined: 21 May 05 Posts: 13 Credit: 5,071,799 RAC: 98 |
Just to follow up, No the computer is not overclocked. I aborted the slow running model. I added the SETI@Home project to confirm that it was not my local Boinc software that was unstable. This was running fine. I changed the settings to us HADAM3P tasks and ever since, the CPDN project tasks have been running normally. If anything comes up about why this happened, I would like to know just out of curiosity. Thanks for all the help guys! Michel ----------------------------------------------- Always keep an open mind, even Einstein could not explain how the universe worked,... |
|
Send message Joined: 28 Nov 06 Posts: 89 Credit: 11,401,696 RAC: 2,591 |
Another question about DHETs - the opinion of project team is very important... It is possible this happened on my hosts occasionally - DHETs \"like\" to drop down the progress to 0%. This may happen on every step... Which way is better? 1. Abort such tasks? 2. Just say a lot of bad words (curse) and let them run again? 
|
|
Send message Joined: 5 Sep 04 Posts: 7629 Credit: 24,240,330 RAC: 0 |
The \"dhets\" are \'slab ocean\' models, (hadsm3), with 3 phases of processing. There\'s a LOT of \"post processing\" at the end of each phase, to create the zip file of data to return to the project. This can take 20-30 minutes, perhaps more on a slow computer, and if this processing gets interrupted, such as by BOINC project switching, or the computer being turned off, then the models have a tendency to rewind to the beginning. As credits are granted per trickle received by the server, and all of the trickles up to the rewind have been logged by the server software and granted credit for them, no more credit will be granted until the model starts returning trickles beyond the previously reached point. What to do after a rewind is up to each cruncher. Backups: Here |
|
Send message Joined: 28 Nov 06 Posts: 89 Credit: 11,401,696 RAC: 2,591 |
The \"dhets\" are \'slab ocean\' models, (hadsm3), with 3 phases of processing. Unfortunately, not always. Earlier this situation was typical for HADSM3 tasks, but now (at least more than 1 year) I see it never - my last rewound task for evidence. What to do after a rewind is up to each cruncher. Restore the task from backup, of course... :-) Unfortunately, this is not always possible. If I understand You correct, there is always a possibility, a rewound task may be finished successful?
|
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
Usually the rewinding would have been caused by interrupting the task during its post-processing at 33.3% or 66.6% or at the end, eg by suspending the task, suspending Boinc activity or exiting from Boinc. A hard reset or power failure at this time would just as risky or worse. All HadSM and HadSM MH models really hate to be interrupted during post-processing. Some members say you shouldn\'t interrupt them until after reaching an extra savepoint (timestep countdown to zero) after the end of post-processing. If a model does rewind and you restore a backup making sure you don\'t disturb the post-processing on the second run, the problem should not reoccur and the model should complete. So in these circumstances the restore of a backup is a good idea. Because these models spend so long on the post-processing, the risk of them being disturbed is higher than with other model types. I wouldn\'t be surprised if all model types are equally at risk during post-processing, but the longer the process the higher the risk. If you haven\'t the time or inclination to make many backups it\'s still useful to make one shortly before the point at which models post-process and create their files. Cpdn news |
|
Send message Joined: 28 Nov 06 Posts: 89 Credit: 11,401,696 RAC: 2,591 |
Usually the rewinding would have been caused by interrupting the task during its post-processing at 33.3% or 66.6% or at the end... Maybe usually, but not always. List of my other latest rewinding HASM3 and HASM3-MH tasks - all 3 dropped the progress to ZERO at unknown step: 10529248 10502063 10492670. Only this task - 10370715 - rewound before sending the last trickle for phase 2. Total I have (for not DHETs) 1/3 (end of phase / unknown). And the CPU time loses are big... Huge... Because this happens on remote machines.
|
|
Iain Inglis Send message Joined: 16 Jan 10 Posts: 1081 Credit: 7,020,145 RAC: 4,560 |
metalius, It is quite common for slab-derived models to rewind at intermediate points other than due to phase-end post-processing, though that is the main cause. Have a look at the following two \'relative seconds/timestep\' graphs. In the first graph, there is a rewind at the end of the second phase. If you look at the model\'s trickle record then you\'ll see the aggregate CPU time approximately double as the third phase starts - the model has restarted from the beginning and the CPU time is therefore twice what it was when it gets to the first trickle after the rewind. The user carried on and the model completed successfully. 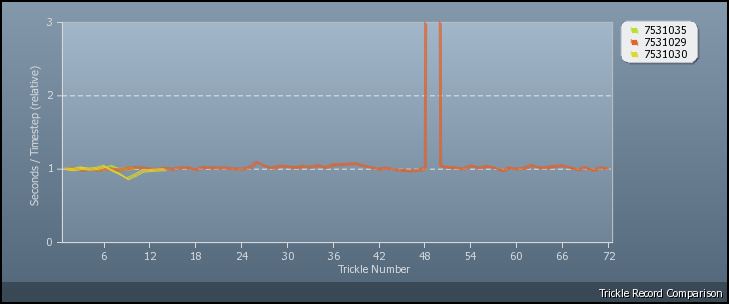 Here in contrast is a rewind during the first phase. The CPU time more than doubles in the trickle record at timestep 108,020. The user is still going - though they would be well-advised to check out their anti-virus or whatever is interfering with the CPDN model\'s progress. 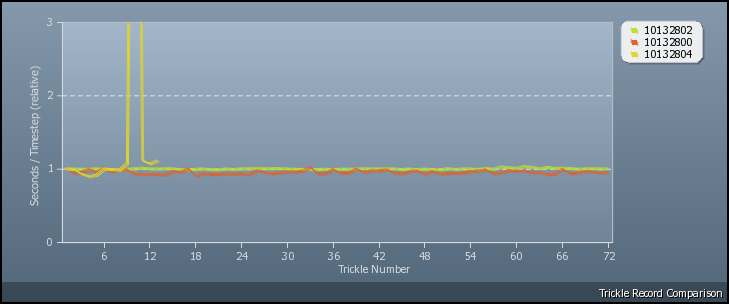 Iain |
|
Send message Joined: 28 Nov 06 Posts: 89 Credit: 11,401,696 RAC: 2,591 |
Les, Iain Thank You for replies. But I have a naive question. :-) If a task goes to ZERO, this means - the task \"forgot\" already passed checkpoints. Why this occasional \"Alzheimer syndrome\" is still not blocked by additional \"if-then-else\"?
|
|
Send message Joined: 5 Sep 04 Posts: 7629 Credit: 24,240,330 RAC: 0 |
Why this occasional \"Alzheimer syndrome\" is still not blocked by additional \"if-then-else\"? It possibly only happens on desktop computers, not on the supercomputers where the code originated. The project\'s two programmers are kind of busy with work needed by paying researchers. I think that Tolu\'s to-do list is backed up into his next life time. :) |
|
Send message Joined: 28 Nov 06 Posts: 89 Credit: 11,401,696 RAC: 2,591 |
It possibly only happens on desktop computers, not on the supercomputers where the code originated. My own experience is - this happens almost never on 24/7 machines, but this is almost usual thing for non 24/7 machines. Let\'s compare 2 my hosts: 24/7 machine - almost 100% of success; remote non 24/7 machine + very slow GSM based connection - pathetic % of success. :-( I think that Tolu\'s to-do list is backed up into his next life time. :) Sad... CPU time loses are very big. By aborting rewinding tasks I can save my points only, but not useful job done.
|

©2024 climateprediction.net